Tooling is the problem, not the type system
I'm firmly in the dynamic typing camp, but I also recognize that some dynamic languages like JavaScript leave a lot to be desired. I think that almost all of the things that might be desired can be addressed with tooling, however, and that tooling can be addressed in three ways.The first way is on the language level. This is best because there's nothing more to do. Common Lisp is more than just a language, it's also a runtime, and a compiler, and the runtime itself ships with a COMPILE function. Normal operation is to COMPILE every piece of Lisp code into assembly and execute it with runtime wrappers (just like C compilers end up converting C to assembly with runtime wrappers around things like calling conventions). The artifacts that go along with being COMPILED let you later tell the runtime to TRACE something, or profile something, or BREAK and debug something step by step (with other much richer debugging options than you normally get with gdb or eclipse with java), they let you ask the runtime "who calls this function?", or "where is this thing referenced?", or "who sets this?" The answers to those questions will be complete as of right now because you're asking a living program.
In Java Land, I commonly ask about who calls what, or to find references for something. It's often slow, and that's even after it's done its indexing work. Yes, in Java Land these questions are derived statically, which means they can be wrong because you might not have statically seen everything, in addition to they might be wrong if they're stale because you're asking again in the future. With Lisp, you just have the second possibility of wrongness. Another advantage is that you tell the Lisp compiler how you want your source compiled right there, in the source, so you can of course tell it to optimize purely for speed and no safety and perhaps not full support for everything that might only be useful at development time.
The second solution to the tooling problem is at the IDE layer. Even Lisp as good as it is by itself can get even better when you integrate it with a dedicated text editor. Check this out (which I got from here, really good mini series to get a feel for what it's like to work with Lisp):
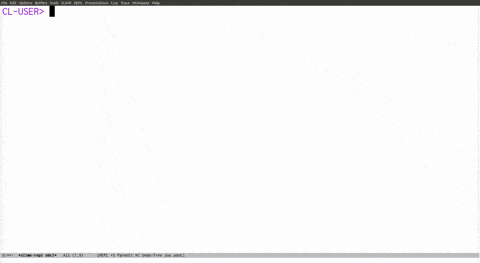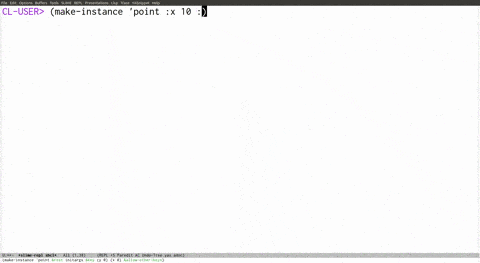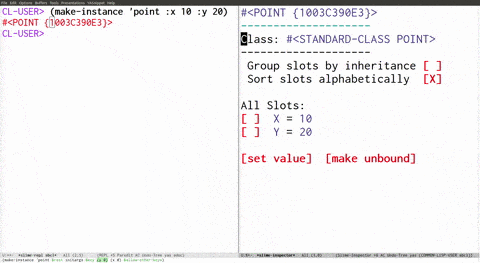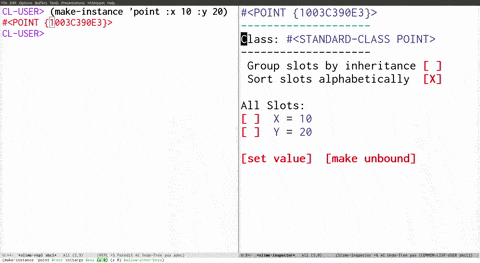
But most dynamic languages aren't Lisp. So what can we do? Personally, I'm a vim guy, but I do make use of plugins. One plugin I like is Syntastic. Essentially it automates the process I've done manually in the past of calling out to a language-specific linter to statically check out your text and see if it makes sense. Linting can almost be seen as a special case of compiling, except because it doesn't have to compile anything, it can actually be configured more broadly and personally. javac doesn't have a flag to let out a warning if your indentation is inconsistent, or if your indentation just doesn't follow the project guidelines even if it's consistent. And why would it? Who calls javac directly? That's something IDEs are responsible for. And anyway that's a super personal and always context sensitive thing, not really something that the serious Compiler should even be capable of calling out as a warning or error. With dynamic languages a similar thing is at play with the runtime, where for the most part it also doesn't make sense for e.g. Node to complain about indentation directly, but your JS IDE probably should.
Well if a dynamic language has a Linter program, you can get a lot of the benefits that people mistakenly attribute to the static type system that are actually part of the IDE. Now of course some features of the type system do matter -- but they're not necessarily limited to static typing. Take one class of problems, which is typo protection. I type the fully qualified name foo.bar in one part of my program, and in another part of my program I type the name foo.bae. Oops! Isn't it convenient that your IDE in your static language highlights it for one of maybe two errors? The IDE doesn't even need to do much work for this feature, it's literally just calling the compiler and the compiler is complaining about foo.bae for some reason. What reason is that? The name cannot be found. However, maybe it can be found, but, the type doesn't match. What happens when the types do match? Well you'll discover your error at runtime. Types don't get rid of testing.
With a linter, the first level of typo protection is also possible. The linter just needs an understanding of the grammar of your language so it can notice when names are being defined and when names are being used, a solved problem. So as long as you give it the full scope of text that makes up your program, it can notice you are using the name foo.bae but it didn't see any definition anywhere, and tell you about it.
Autocomplete? Yeah have had that for ages too. Even in vim! If you want it. Depending on the language it can actually be super easy for the IDE to implement because the IDE can just ask the runtime what things are callable on this thing and filter by the prefix, and if the runtime contains the documentation like dynamic languages tend to do, the IDE can use that doc and it's never out of date (or rather out of sync with the running code, docs can always lie).
Incidentally, Lisp can report that foo.bae is undefined when you compile the code it appears in, and it can report about mismatched typing if you've specified such things. At compile time, and at run time.
The third solution of the tooling problem is to write simpler, value-oriented, language-standard code and have a simpler deployment process. The first part of that alone can help with the second solution tremendously because now the work for linters and IDEs is lessened. I'm sad to say that my Eclipse workspace at work is nifty for our Java code but it tells me absolutely nothing of use about our JS code, and it's not like Eclipse doesn't support JS linters. It's because of the way the JS code is structured and linked and there's an impedance mismatch with how Eclipse wants to understand it. The second part is rather important too. A lot of people write languages that compile to JavaScript, and that's what they deploy. That extra step matters. And now your IDE has to support the new language while also understanding that it's going to end up in a JS context. Difficult.
In the end though, simpler, value-oriented code ought to be preferred everywhere. Don't create a 10-element Enum (or enum-equivalent) that you need to check every value of to switch on in 10 different places in the code. With a static language with good tooling, ok, when you add an 11th enum, you can find all the places it's referenced (even if aliased) and make sure to check it in all of them. In some more powerful static languages, you can do an exhaustive switch, so the compiler will complain that you didn't check the new value in each place, no need to rely on external tooling. But the idea was probably bad from the start. And you know what tool will find all references anyway? grep. If you've aliased them, it might not find the aliases, and that's where IDEs can help, but generally you should strive to write greppable code. Or more commonly for me, write ag'able code, which is a tool to simplify recursively grepping every file for a string.
Avoid bozo things like "private static final String UNDERSCORE = "_";". Please. That crap makes it into production code, it shouldn't. If you want a schema, create a schema elsewhere, don't make ad-hoc private-only renames of pure data. When you write greppable code, regardless of the language (C, a statically typed language, didn't come out of the box with all the refactoring support we take for granted and like to think is only possible because of static typing -- we ignore that Lisp and Smalltalk did and basically had it all) I'll be able to get by. If I have to, I can use print line debugging. And for that style of debugging, dynamic types definitely win because you don't need a manual compile step. (Yes, I'm aware that some static languages have or are getting limited REPLs. Let me know when I can SFTP my code in the source language, and nothing else, to some folders on my web server and have it all work.)
Sometimes I don't get why static languages seem to be gaining traction rather than losing it, when for maybe most of this century it was the opposite. Maybe my perception is skewed. But if it's not, I'm curious what the reasons might be.
It might be worth asking why dynamic languages gained in the first place. One possible explanation for both the rise and fall comes to mind which is computing power. From the 90s to around 2009 computing power kept increasing a lot. This meant language authors could maybe create something that was more expressive but computed more to support it. You might also interpret it as "real interpreters can be fast now, let's just use one of those and ship source (we can also edit it at the destination!)" before everyone (if they weren't already) had to compile to bytecode, machine code, and/or run a JIT. I can't imagine this blog being written in C. Ok I can, but it'd be a pain to update anything. What, I'm going to compile locally and then ship a binary? And what if I have a serious error I need to fix in production? I have to be at my dev machine? Why can't I just login from wherever I am, and edit the source? In fact if I did use C I'd probably make sure the server has a compiler on it just so I can get that edge case benefit. Anyway, as computing power has leveled off, performance matters more again, and static typing does help there. (At least, it should to be worthwhile at all in my mind...)
Another explanation is that they were more productive in other ways, but modern static languages + their tooling are closing the gap. No one SFTPs to deploy anymore, they just run one script or click a button or maybe they don't even do anything if it's an automated process on another machine. This is independent of language. Library access is better all around. When Perl had CPAN, it was amazing. Now every language has something more or less as simple. A lot of the dotting is and crossing ts of modern static languages has been removed, either by actually less typing (e.g. the 'auto' keyword, diamond operator, other inferences..) or just from IDE auto-complete convenience. Many features like first class functions have made their way to the most popular static languages, too. So there's less benefit to most dynamic languages than there used to be. I kind of like this explanation, and I think it helps explain why lots of Python programmers are moving to languages like Rust, Nim, OCaml, or even Go, rather than other languages like C++ or Java despite those languages now catching up quite a bit too.
Another explanation is that people get forced into legacy dynamic projects from the early 2000s but no one has shown them the proper tooling to make it nice to work with. They come off with a bad experience, and generalize to all dynamic languages. I'm pretty sure if you had any Python skeptic watch the PyCharm video their worries would melt away. But if they've had essentially no support besides a plain text editor, I can see the frustration, even if I don't understand the mentality that kept them from looking at fixes (such as grep, ag, or a different IDE or editor). Or a simpler version of this explanation is basically that people don't try anything and generalize poorly. Common Lisp is really the exception to every complaint about dynamic languages coming from a normal static typing user perspective, but they're oblivious to it. Why?
Posted on 2017-10-13 by Jach
Tags: programming, rant
Permalink: https://www.thejach.com/view/id/346
Trackback URL: https://www.thejach.com/view/2017/10/tooling_is_the_problem_not_the_type_system
Recent Posts
2025-03-15
2025-03-03
2025-02-13
2025-01-14
2025-01-10